
According to the latest definition from Gartner, Artificial Intelligence Operations (AIOps) integrates big data and machine learning to extract and analyze the growing volume, variety, and velocity of data in a scalable and loose-coupling manner, supporting IT Service Management platform. To share our daily practice and front-line experience with peers, the WeBank AIOps team has written article series on the subject of AIOps.
IT operations emerged with the establishment of big tech companies, which was more about computer maintenance and network administration. Anything computer-related was within the scope of IT Ops. As technology advanced, the responsibilities and roles of IT position refined and transformed to form the IT Ops functional department that oversees business continuity nowadays. The values of IT Ops has emerged with the outbreak of various technologies in the past 10 years.
The following diagram illustrates the five stages of IT Ops development: from manual and process-oriented in the early phases to the latest AIOps. As an essential experimental field for new technologies, the development of IT Ops has been inseparable from technology advancements.
For enterprises, the value of IT Ops reflects on business stability, operational safety, and cost reduction. As traditional businesses go digital, operational stability and data security have become critical indicators of profitability. The trade-off between efficiency and cost is a challenge faced by many enterprises, as IT costs weight more on their balance sheets.

The transformation of IT Ops towards DevOps or AIOps is inevitable. DevOps has achieved rapid response, high-quality delivery, and continuous feedback by connecting all development tools in applications’ entire lifecycle, utilizing automation and cross-team online collaboration.
Enterprises applying AIOps in business operation and production support have better IT support in cost control, quality management, and efficiency enhancement. Currently, the main application scenarios of AIOps include anomaly alert, alert convergence, failure analysis, trend forecast, etc.
Here are some case studies of AIOps implementation in Chinese tech giants.
1) AIOps practice of China’s multi-service platform Meituan
In the 2019 Summit of Global Leadership Technology Committee, Bin Song, a senior tech expert from Meituan, talked about the company’s extremely challenging quasi-real-time logistics business in terms of system stability, including high peak traffic, large instantaneous peaks, long service links, online business complexity, failure sensitivity. The aforementioned problems affected order fulfillment, and resulted in compensation and customer complaints. After more than a year of hard work, Meituan had gradually shifted manual Ops to automated Ops, with attempts to use machine learning for efficiency enhancement. Song’s sharing revealed the gradual process of Meituan establishing a comprehensive and reliable automated Ops system with capacity assessment, flexibility design, failure diagnosis, and risk prevention.

Failure diagnosis includes failure detection and root cause analysis (RCA). It clarifies what failures are, how they look like, and what the root cause is. Meituan presented failure information in both developer’s and manager’s perspectives. The core function of failure diagnosis includes failure convergence, link monitoring, failure topology display, and alert escalation, etc. It labels, operates, manages, and tracks failure at the same time.
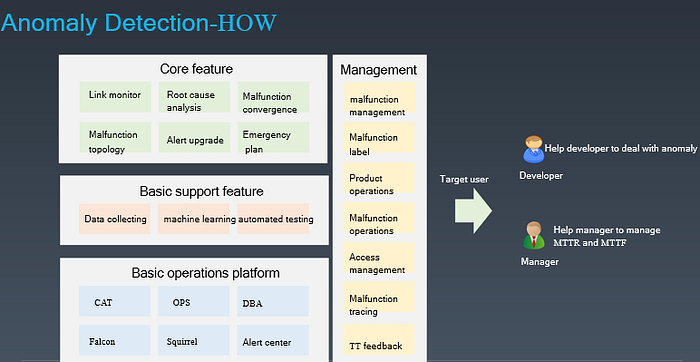
Meituan RCA uses not only the conventional vertical analysis, which is root cause mining, but also an innovative horizontal analysis- the recursive relation of a call link.
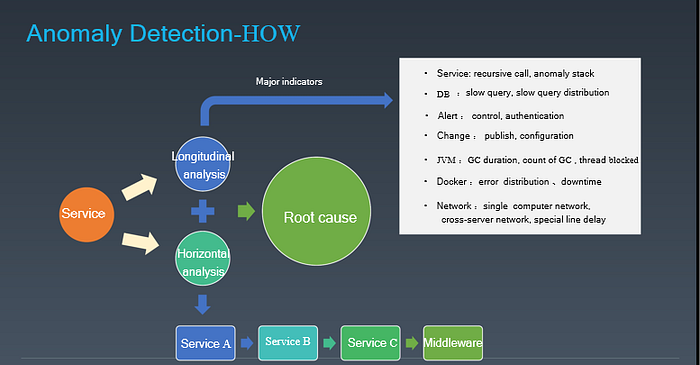
Judging by the result, less location time and borderer detection coverage have massively reduced operation costs. The entire IT Ops support system adopts machine learning in the end-to-end link monitoring and dynamic thresholds of failure rate monitoring, which is anomaly detection based on the LOF (local outlier factor) algorithm. Rules are supplemented in the meanwhile.

2) AIOps ofBaidu
At the 2019 ArchSummit, two senior R&D engineers from Baidu Zhou Wei and Fan Yuelin presented a case study of Baidu using AIOps to merge the two monitoring scenes of intelligent anomaly detection and intelligent alert.
The diagram below illustrates the architecture of Baidu’s alert system.
In the anomaly detection stage, the main challenges were the frequent changes in models and algorithms. To solve the problem, Baidu separated models and algorithms, and shortened iteration from months to days. The platform that verifies the algorithm strategy was divided into an offline environment, a near-line environment, and an online environment, so that the algorithms can be verified in a reliable data environment.
Hyperactive alerts will challenge system stability if they are not merged. Baidu made mergers by deployment architectures as well as across different deployment architectures. The merging by deployment architectures was mainly based on the relationships in the configuration management system, while the merging across architectures relied on the upstream and downstream relationships and offline strategy mining.
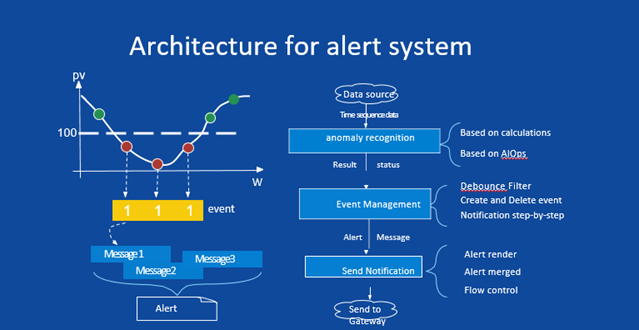
As a result, critical monitoring KPIs have been significantly improved. Anomaly detection is highly effective, and the amount of SMS alert has been greatly reduced.

3) WebBank AIOps practice in anomaly detection and RCA
WeBank achieved favorable outcomes in the application AIOps in 2019 by utilizing machine learning algorithms in multiple scenarios.
For anomaly detection, WeBank defined key business indicators (e.g., transaction volume, business success rate, system success rate, and average transaction time per unit) by a service availability-centric approach. The indicators are monitored and measured by a combination of algorithms and expert rules.
For RCA, WeBank replaced the traditional location method using expert experience and alarm component, with an approach that started from the interrupted subsystem and used knowledge graph to proceed. The interrupted subsystem was located by the transaction tree, which is generated by algorithms with the message queue as the foundation.
In addition, the historical data of anomaly events was also imported into the knowledge graph to correct the expert experience. Anomaly recognition and root cause analysis were performed on the perspective of operation management and the basic model was continuously revised.
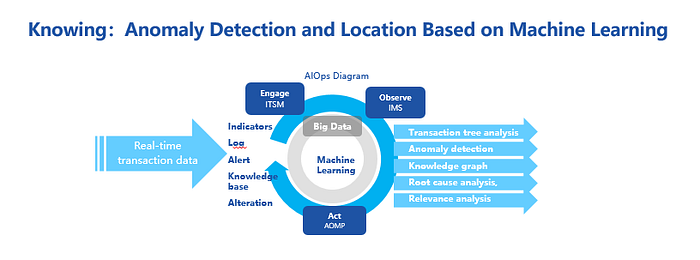

In 2019, the accuracy of anomaly recognition was 96% at WeBank, and notification omission was less than once in every three months. Anomaly notification time was 66% less than it was in 2018. The root cause location was completed within 5 minutes after an anomaly occurrence. Anomaly recognition and RCA had been significantly improved.
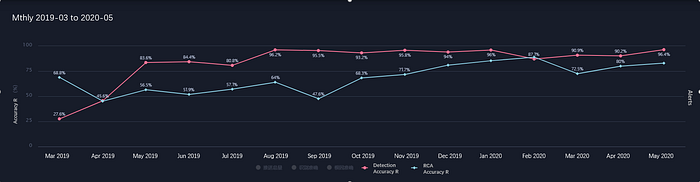
From the three successful cases above, five characteristics of present AIOps practices can be concluded.
1. In AIOps, the best machine learning application is the detection of anomaly indicators, because of low cost — in both engineering and developer resources perspectives, and high effectiveness. Once implemented, the production support staff will receive the most direct benefits.
2. Various RCA scenarios can be derived from the anomaly indicators application as a starting point. An analysis of the anomaly is required once detected. Both Meituan and WeBank have made breakthroughs in root cause location by using transaction links.
However, WeBank’s approach of a gradual transformation from pure data-based ML to the logic level distinguishes its application from that of Meituan. In WeBank’s case, automated annotation integrated algorithms and message bus, while Meituan took a manual approach.
3. Algorithm is not an answer to all. However, the combing algorithm with actual (expert) rules can bring desirable results. That’s a valuable lesson learned from AIOps application to solve the problems of IT operations practically.
4. Standardized data in the data warehouse provides the foundation for machine learning, while massive basic data from daily IT Ops is the prerequisite of machine learning. Also,
centralized organizational structure and operational tool management will benefit the adoption of AIOps.
5. The next direction for AIOps to explore is prediction, such as dynamic capacity prediction or event prediction. Proactive monitoring and projection will be the primary challenges in the future.
IT architecture has gradually shifted from the traditional “IOE” to the Internet (distributed); operation system from ITIL to DevOps; operations platform from automation to AIOps. Meanwhile, the focus of IT operations has shifted from platforms to digital assets. AIOps is the trend of IT operations in the future. All aspects of Internet business continuity will undergo tremendous changes in this process. AIOps will play an irreplaceable role in a growing number of scenarios.
Chinese author: Anna Wang
Translator: Tony Su
Editors: WeBank AIOps Team
